
|
SVETLANA LAZEBNIKProfessorDepartment of Computer Science University of Illinois at Urbana-Champaign Office: 3308 Siebel Center Phone: 217-300-2422 Email: slazebni -at- illinois.edu Google Scholar, CV |
I received my Ph.D. at UIUC in May 2006 under the supervision of Prof. Jean Ponce. From August 2007 to December 2011 I was an assistant professor at the University of North Carolina at Chapel Hill, and as of January 2012, I have returned as faculty to U of I. My research specialty is computer vision. The main themes of my research include scene understanding, joint modeling of images and text, large-scale photo collections, and machine learning techniques for visual recognition problems.
Current and former sources of support for my research include the National Science Foundation (under grants IIS 1718221, IIS 1563727, IIS 1228082, CIF 1302438, and IIS 0916829), Amazon Research Award, AWS Machine Learning Research Award, Microsoft Research Faculty Fellowship, Xerox University Affairs Committee Grants, DARPA Computer Science Study Group, Sloan Foundation Fellowship, Google Research Award, ARO, and Adobe.
Ph.D. Students
- Aiyu Cui
- Viraj Shah
- Shivansh Patel
- Ayush Sarkar
Former Ph.D. Students
- Daniel McKee -- Ph.D. 2023, now at Snap
- Unnat Jain -- Ph.D. 2022 (co-advised with Alex Schwing), now postdoc at Meta AI/CMU
- Arun Mallya -- Ph.D. 2018, now at NVIDIA Research
- Liwei Wang -- Ph.D. 2018, now Assistant Professor at the Chinese University of Hong Kong
- Bryan Plummer -- Ph.D. 2018, now Assistant Professor at Boston University
- Yunchao Gong -- Ph.D. 2014 (UNC), now at Verkada
- Joseph Tighe -- Ph.D. 2013 (UNC), now at Meta
Former Postdocs
- Tatiana Tommasi -- UNC (2015-2016, co-advised with Tamara and Alex Berg), now at Politecnico di Torino
- Juan Caicedo -- U of I (2012-2014), now at Broad Institute of MIT and Harvard
Teaching
- Spring 2024: CS 444 Deep Learning for Computer Vision
- Fall 2023: CS 598 Computer Vision: What Will Stand the Test of Time?
- Spring 2023: CS 444 Deep Learning for Computer Vision
- Fall 2022: CS 543/ECE 549 Computer Vision
- Spring 2022: CS 444: Deep Learning for Computer Vision
- Fall 2021: CS 543/ECE 549 Computer Vision
- Spring 2021: CS 498 DL: Introduction to Deep Learning
- Fall 2020: CS 498 DL: Introduction to Deep Learning
- Spring 2020: Computer Vision: Looking Back to Look Forward (IRIM Visiting Faculty Fellow Short Course)
Research Highlights

|
Virtual Try-On, Image Stylization
|

|
Video Tracking and Label Propagation
|
|
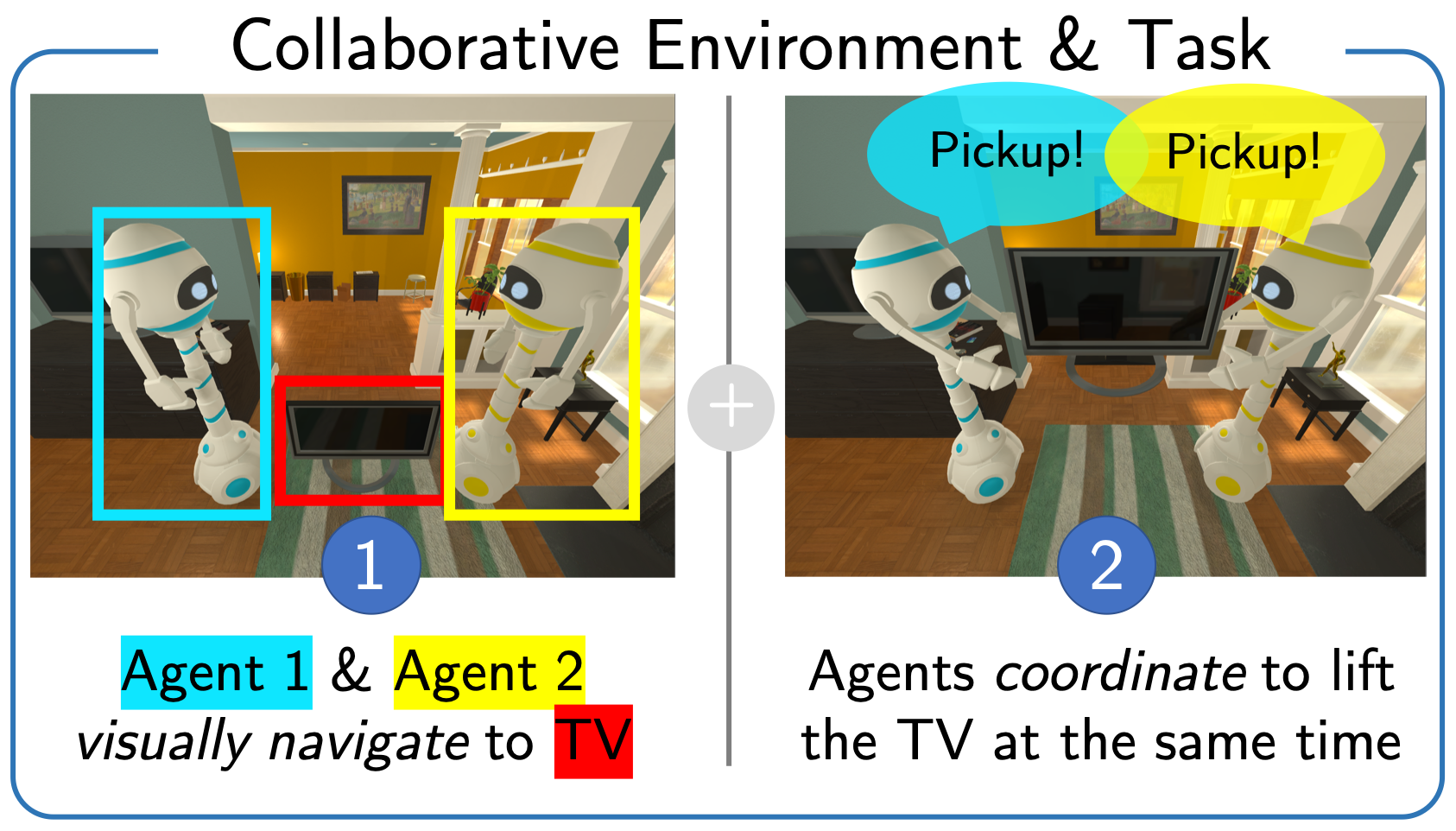
Collaborative Embodied Agents
|
Past Projects








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Personal
- I was born in Kiev, Ukraine. If you want to learn more about my birth date, you can read this essay I wrote in high school.
- My husband and scientific collaborator: Maxim Raginsky.
- I take photos from time to time. Check out my Flickr account.

Last updated December 18, 2023