Fall 2018 CS498DL
Assignment 4: GANs and RNNs
Due date: Tuesday, December 4th, 11:59:59PM

Sample images from a GAN trained on the Celeb A dataset
This assignment has two parts. In the first you will use a generative adversarial network to train on the CelebA Dataset and learn to generate face images. In the second part, you will train an RNN for two tasks on text data: language classification and text generation. In the generation task your RNN will learn to generate text by predicting the most likely next character based on previous characters. In the language classification task, your RNN will learn to detect which language a chunk of text is written in (similar to a feature you might find in an online translator). While this might be relatively easy to do if the input text is unicode and unique characters indicate a particular language, we address the case where all input text to converted to ASCII characters so our network must learn instead to detect letter patterns.
In addition to familiarizing you with generative models and recurrent neural networks, this assignment will help you gain experience with how to implement GANs/RNNs in PyTorch and how to process text data for character based prediction tasks.
This assignment was adapted from and inspired by material from the Stanford CS231n Assignments, Andrej Karpathy's RNN blog post , and the PyTorch Tutorials.
Download the starting code here.
Part 1: Face Generation with a GAN
Data set up
Once you have downloaded the zip file, go to the Assignment folder and execute the CelebA download script provided:
cd Assignment4/
./download_celeba.sh
The Celeb A data provided to you is a preprocessed version which has been filtered using a simple face detector to obtain good images for generation. The images are also all cropped and resized to the same width and height.
Implementation
The top-level notebook (MP4_P1.ipynb) will guide you through the steps you need to take to implement and train a GAN. You will train two different models, the original GAN and LSGAN, which has a different loss function. The generator and discriminator network architectures you will implement are roughly based on DCGAN.
We also provide with a notebook to help with debugging called GAN_debugging.ipynb. This notebook provides a small network you can use to train on MNIST. The small network trains very quickly so you can use it to verify that your loss functions and training code are correct.
You will need to use a GPU for training your GAN. We recommend using Colab to debug, but a Google Cloud machine once your debugging is finished as you will have to run the GAN for a few hours to train fully.
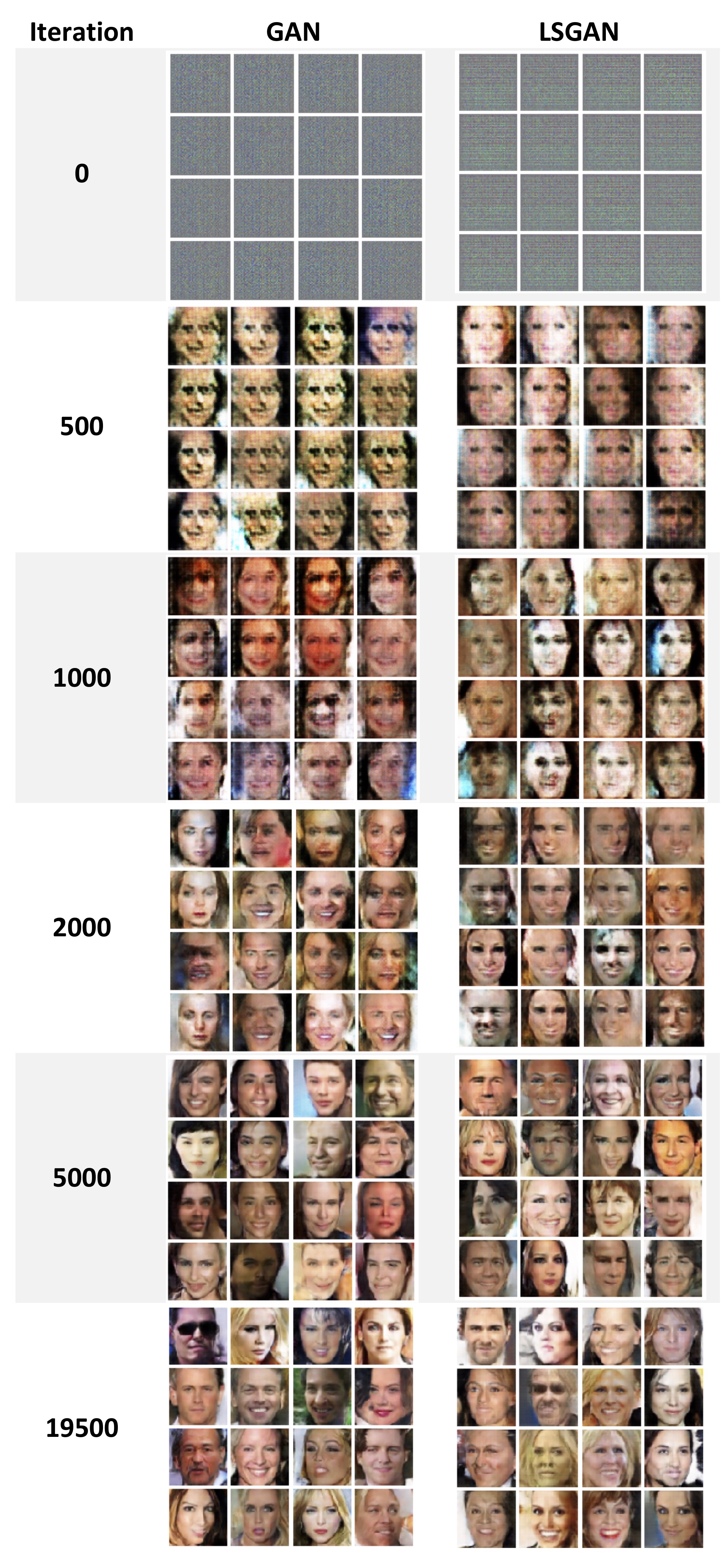
GAN output images during training (each iteration has batch size of 128)
Extra Credit
Extra credit options for this portion of the assignment:- Change the network architecture and hyperparameters to train on the full 128x128 resolution CelebA data in the preprocessed dataset we provide rather than the 64x64 resized samples we train on currently.
- Implement one of other the recent GAN modifications like WGAN/WGAN-GP, DRAGAN, or BEGAN.
References:
- Lecture material (lecture 13 on GANs)
- A nice blog post series including introductory posts along with posts on DCGAN and LSGAN
- Generative Adversarial Nets paper
- LSGAN paper
- DCGAN paper
Part 2: Text Generation and Language classification with an RNN
Data set up
To download the data for the RNN tasks, go to the Assignment folder and run the download_language_data python script provided:
cd Assignment4/
python download_language_data.py
The data for the generation task is the complete works of Shakespeare all concatenated together. The data we use for the language classification task is a set of translations of the Bible in 20 different Latin alphabet based languages (i.e. languages where converting from unicode to ASCII may be somewhat permissible).
Extra Credit
For extra credit in this portion you may download or scrape your own dataset. Your data could be a book from Project Gutenberg by your favorite author, a large codebase in your favorite programming language, or other text data you have scraped off the internet.References:
- Lecture material (lecture 15 on RNNs)
- Andrej Karpathy's RNN blog post
- Another blog post on LSTMs
Implementation
This part of the assignment is split into two notebooks (MP4_P2_generation.ipynb and MP4_P2_classification.ipynb). The MP4_P2_generation.ipynb will guide you through the implementation of your RNN model. You will use the same model framework you implement for classification portion in the MP4_P2_classification.ipynb notebook.
Both of the RNN tasks in this assignment are not as computation heavy and can be trained in a short amount of time on GPU or CPU.
Environment Setup (Local)
If you will be working on the assignment on a local machine then you will need a python environment set up with the appropriate packages. We suggest that you use Conda to manage python package dependencies (https://conda.io/docs/user-guide/getting-started.html).
IPython
The assignment is given to you in the MP4_P2.ipynb file. To open the files on a local machine, ensure
that ipython is installed (https://ipython.org/install.html). You may
then navigate the assignment directory in terminal and start a local ipython server using the jupyter notebook
command.
Submission Instructions
This part of the assignment is due on Compass on the due date specified above. You must upload the following files for this part.
- All of your code (python files and ipynb file) in a single ZIP file. The filename should be netid_mp4_code.zip.
- Your ipython notebooks with output cells converted to PDF format. The filenames should be netid_mp4_part1_output.pdf, netid_mp4_part2_classification_output.pdf, and netid_mp4_part2_generation_output.pdf.
- A brief report in PDF format using this template. The filename should be netid_mp4_report.pdf.
- Submit an output Kaggle submission CSV file on a provided test subset for the RNN classification task to Kaggle competition.
Please refer to course policies on collaborations, late submission, and extension requests.